An explainer on how machine learning libraries can optimize any function.
Jinay Jain - Jul 27, 2020
Before reading, you can try out my interactive visualization tool for a primer on what I’ll discuss below.
At their core, neural networks are functions. They take some input, perform a series of computations, and produce an output. Though most networks operate in the realm of vectors and matrices, it can be a useful exercise to see them without the extra barrier of linear algebra. For this purposes of this explanation, we will only cover single variable functions, but the principles we will see can be extended into any number of dimensions.
The Forward Pass
Before we reach the backwards propagation of gradients, we will observe the forward propagation of values. The forward pass provides a reasonable basis for understanding how functions can be represented as the result of other functions combined. Finally, we can represent these functions as a computation graph—an idea which will be useful when we arrive at the backward pass of the function.
Function Composition
We begin with the most basic function, mapping the entire range of inputs to a single number.
Simple, right? Let’s try to incorporate into the mix by creating the identity function—any in will be the same out.
The power comes when we can compose the functions using different operations, building a new function from the existing ones. By composing functions together, we can evaluate the individual functions before we evaluate the parent.
Likewise, we can feed the output of one function as the input of another, increasing the complexity of the overall function while retaining its individual parts.
Intuitively, a human would first calculate the value of before squaring the result. This staged ordering creates a hierarchy of functions that our algorithms can harness.
We see this type of hierarchy building when we build models in any machine learning library. What TensorFlow calls a “model” is just a series of computations composed into a single function.
model = tf.keras.Sequential()
model.add(Dense(512))
model.add(Dense(512))
...
model.add(Dense(32))
model.add(Dense(10))
# Outputs the result of sequentially feeding X through the Dense layers
y = model.predict(X)
Every time we call model.add(), we are adding to the hierarchy that defines
our neural network. In machine learning, composed functions defined
earlier are less like and more like
Each is a layer in the network which produces an output by using the previous layer as input.
Building a Computation Graph
We can visualize a composed function’s structure as a tree, each layer representing a different stage of the operation. In fact, most programming languages use a parse tree to store and evaluate expressions in code. This representation gives us the ability to view a function in terms of its component parts, recursing down the levels until we find the constants and variables at the very bottom.
For example, take the function given below.
In machine learning, this is a function called the sigmoid, often written as . Let’s see how we could break the sigmoid into a computation tree.

Notice how all four leaf nodes are either a constant or a variable. These are the most elementary parts of any composite function. We can even give the intermediate functions letter names to highlight how each node is built from its children.

The equations for our new tree would be
The Backward Pass
Up until this point, viewing functions as hierarchies seems to add unnecessary abstractions on a relatively simple topic. However, now that we have observed how to compute the “forward pass” of a computation graph, we can compute the reverse using an algorithm called backpropagation.
Gradient Descent
In machine learning, the end goal is to minimize error on a loss function, and modern software achieves this goal through an algorithm called gradient descent. Though I will not attempt to explain the entirety of gradient descent here, a basic understanding of how it works is essential for understanding backpropagation.
Loss functions measure how much the outputs of a model, the neural network, deviate from the labels in a dataset. Tuning the parameters of the model will either increase or decrease that loss, and the goal is to find the set of parameters that will give us the minimum loss. Through gradient descent, we try to estimate which direction we should tune our model in order to achieve the optimal settings.
Imagine we have a loss function that measures the performance of a model with only one parameter, . The graph of could look something like this graph:

From this zoomed out perspective, the valley in the curve (where loss is the lowest) is obvious. However, when we train a model, this view is significantly smaller, giving us only information about how the loss curve looks near the current value of .
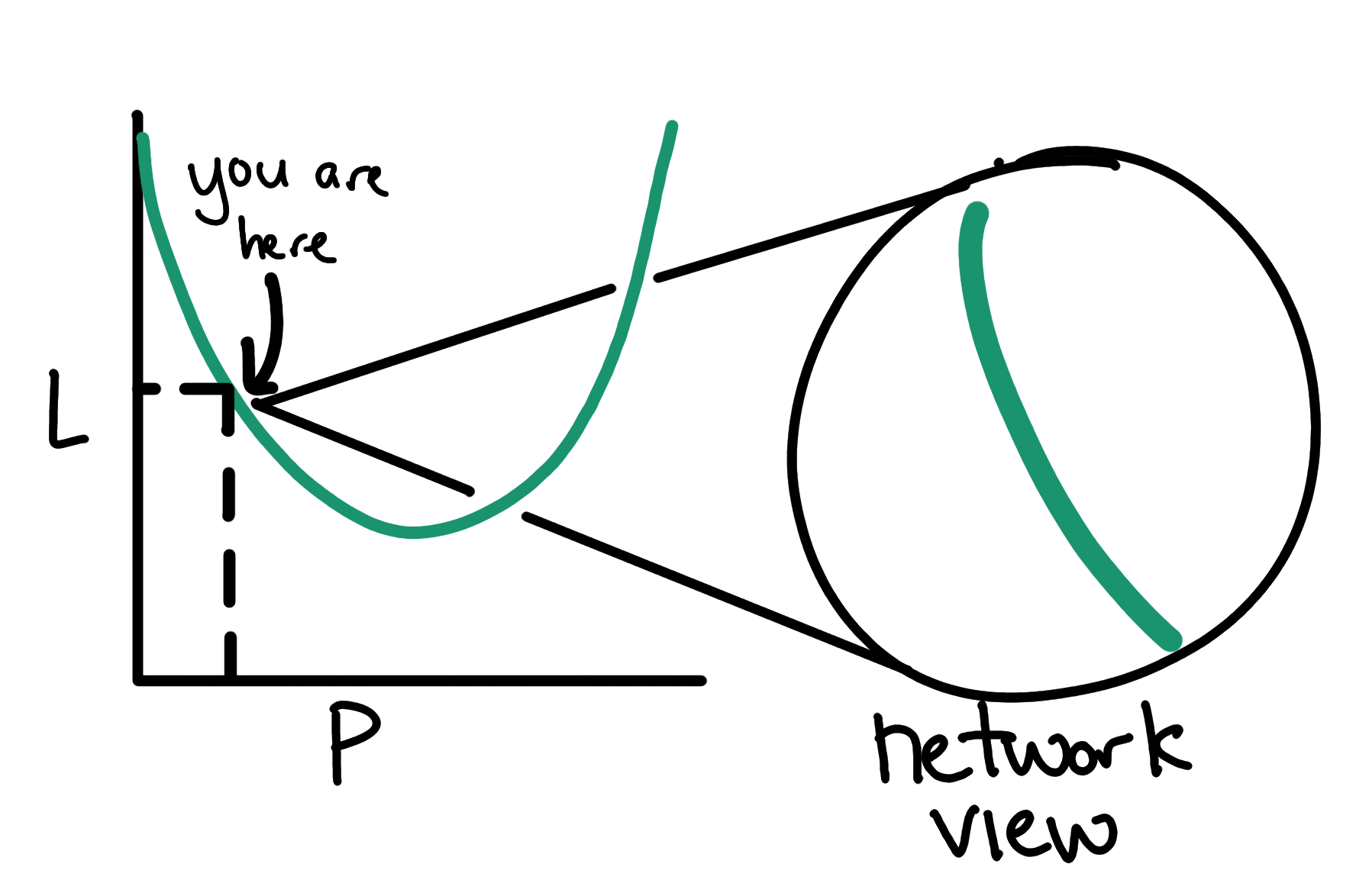
Intuitively, we should follow the direction that has the steepest slope downwards to find the minimum. In mathematical terms, we want to look at the gradient of and take a small step in the direction down that gradient.

Backpropagation is the tool that helps a model find that gradient estimate so that we know which direction to move in.
Backpropagation
The gradient is a collection of slope calculations called the partial derivatives. Both partial derivatives and gradients answer a question that is fundamental to our purpose: how does a small change in a variable respectively change the output function . In machine learning, we want to observe how changing will change the loss.
Before we begin, let us revisit some of the basic rules of calculus that are crucial to understanding backpropagation. When computing partial derivatves, we consider other variables of the functions constants, so represents any constant or variable other than .
There are many more rules, but these basics encompass a large portion of what functions you might see in machine learning applications. However, using only these rules, our function vocabulary is significantly limited. We can only take partial derivatives for simple functions like or if we are clever. The essential property for achieving infinitely complex functions is a rule most calculus classes group with the rest.
The chain rule enables us to unravel the composed functions we discussed earlier—giving us the ability to compute arbitrarily complex partial derivatives and gradients. Using the computation graph we constructed earlier, we can move backwards from the final result to find individual derivatives for variables. This backwards computation of the derivative using the chain rule is what gives backpropagation its name. We use the and propagate that partial derivative backwards into the children of .
As a simple example, consider the following function and its corresponding computation graph.

As earlier, we assign the intermediate computations letter names to use in calculation. Let’s find , the slope of , when . First, let’s compute the forward pass of the function, labelling the intermediate values of each node until we reach .
Starting from the top, let us find the partial derivatives of the tree on the path down to . As we traverse down the tree, it only makes sense to take the partial derivatives with respect to the branches that is a part of.
Since is a direct child of g, the chain rule is not necessary here. Knowing the values of and from the forward pass, we can find a numerical value for the partial derivative.
The next node in the path is , a direct child of the previous node . To find the “local” partial derivative, we use the addition rule. is 0 since a small change in makes no change in
To find the desired value of , we can finally employ the chain rule.
Finally, we arrive at node , the node containing . The process for finding this derivative is identical to the previous ones.
We’ve arrived at the end of the path to , giving us the final value of .
I encourage you to revisit my visualization
tool and play around with various
functions, tracing the path of the gradients down to your original variables.
You might even want to try (4*x+1)^2 and see how the gradients change as
changes.
This simple algorithm for calculating partial derivatives on a computation graph is very similar to the way neural networks are trained in libraries like Tensorflow. A firm understanding on how the libraries work allows you to expand your capabilities beyond the prepackaged layers they provide. More importantly, it allows you to gain insight on the algorithms used every day to train computers on any amount of data.
The task remains constant—minimize error on a loss function.
Additional Resources
This post was inspired by the insightful explanations of backpropagation linked below.
Stanford CS231n - Backpropagation, Intuitions